Makefile 与 make/.mk 语法教程:从入门到进阶精通
本教程致力于为具备基础编程背景的工程师和学生提供一份详尽的 Makefile 与 make 语法指南。我们将从最基础的概念出发,循序渐进,直至进阶应用与工程实践,力求将复杂的构建体系知识拆解为清晰易懂的学习路径。无论你是初次接触 Makefile,还是希望系统性地巩固和提升,都能从中获益。
一、入门基础:与 Make 的第一次亲密接触
make 是一个历史悠久但至今仍在广泛使用的构建自动化工具。它通过读取名为 Makefile 的文件,来理解项目各个部分之间的依赖关系,并执行必要的命令来生成最终的目标产物(例如可执行文件、库、文档等)。
1.1 三要素:目标(Target)、依赖(Prerequisites)和命令(Recipe)
一个 Makefile 的核心由一系列“规则”(Rule)构成,每条规则包含三个基本要素:
- 目标(Target):规则所要构建的产物,通常是一个文件名,也可以是一个抽象的动作名称(如
clean)。 - 依赖(Prerequisites):构建“目标”所需要的文件或其他的“目标”。
- 命令(Recipe):用于从“依赖”生成“目标”的 Shell 命令序列。
这三者构成了 make 的基本工作模式:
# 格式
target: prerequisite1 prerequisite2 ...
command1
command2
...
关键原则:制表符(Tab)规则make 对格式要求极为严格:每个“命令”行的行首必须是一个且只能是一个制表符(Tab),而不能是空格。这是 Makefile 语法中最常见也是最容易出错的一点。如果你的编辑器将 Tab 自动转换为空格,将会导致 make 无法识别命令,并报错 *** missing separator. Stop.。
1.2 最小示例:编译一个 C 程序
让我们通过一个经典的 hello.c 示例来理解这个过程。hello.c 文件:
#include <stdio.h>
int main() {
printf("Hello, Makefile!\\n");
return 0;
}
Makefile 文件:
# 这是一个注释
# 规则一:定义如何生成可执行文件 hello
hello: hello.o
gcc -o hello hello.o
# 规则二:定义如何从源文件生成目标文件 hello.o
hello.o: hello.c
gcc -c hello.c
# 这是一个“伪目标”,我们稍后会详细解释
clean:
rm -f hello hello.o
现在,在包含这两个文件的目录中,你可以执行以下命令:
make或make hello:make会查找第一个目标(hello)并尝试构建它。它发现hello依赖hello.o,于是又查找构建hello.o的规则。hello.o依赖hello.c,由于hello.c已经存在,make就会执行gcc -c hello.c来生成hello.o。当hello.o生成后,make回到第一个规则,执行gcc -o hello hello.o来生成最终的可执行文件hello。make clean:执行名为clean的目标所对应的命令,即删除生成的文件。
这个过程清晰地展示了 make 的工作逻辑:它构建一个有向无环图(DAG),从目标出发,逆向检查依赖,直到找到已经存在的文件或无需依赖的目标,然后再正向执行命令,最终完成构建。
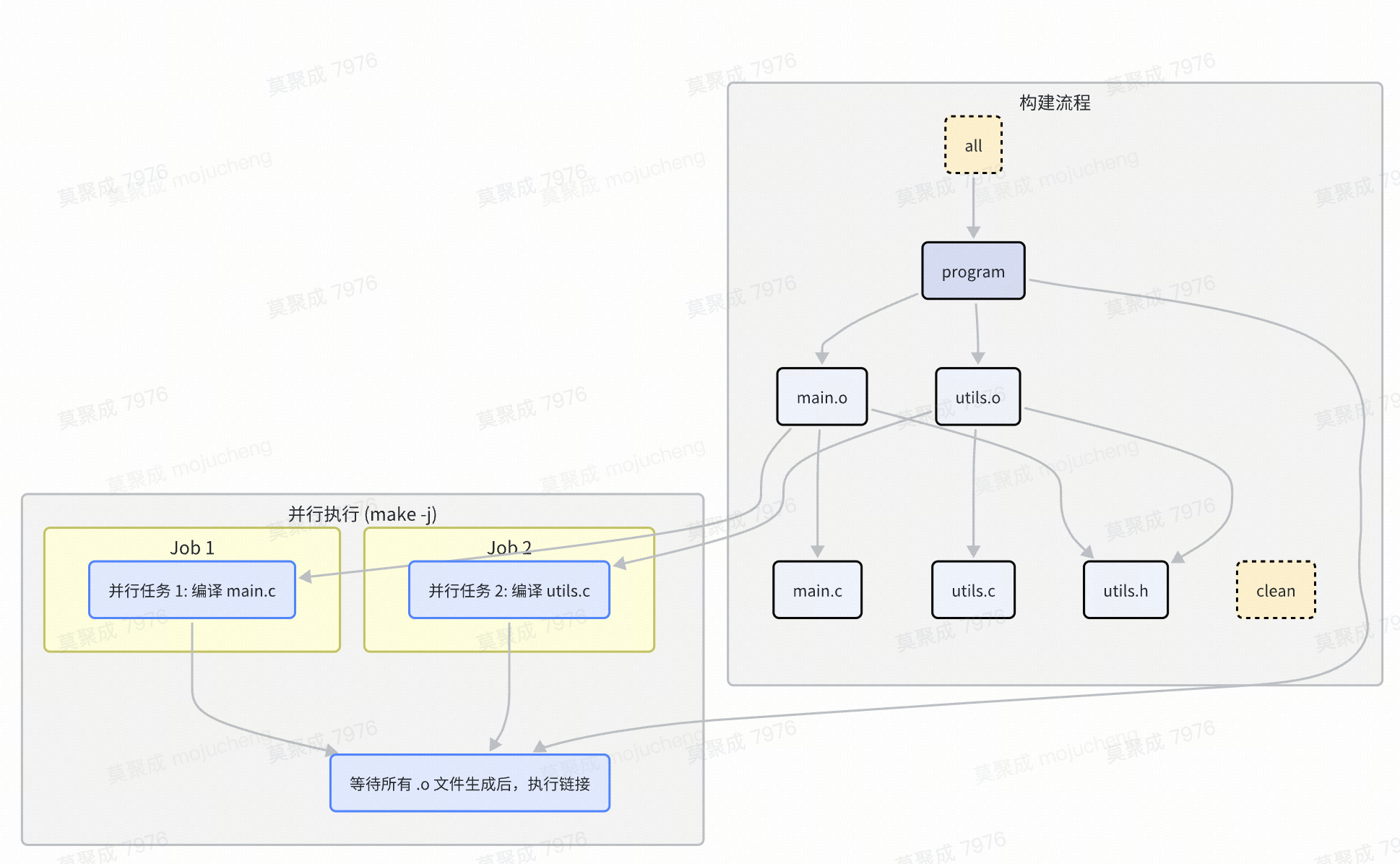
1.3 .PHONY:定义“伪目标”
在上面的例子中,clean 并不是一个文件名,而是一个动作的标签。这种不代表实际文件的目标被称为“伪目标”(Phony Target)。我们推荐总是使用 .PHONY 来明确声明伪目标:
.PHONY: all clean install
all: hello
hello: hello.o
# ...
clean:
rm -f hello hello.o
install:
cp hello /usr/local/bin/
为什么要使用 .PHONY?
- 避免与文件名冲突:如果在你的目录下恰好存在一个名为
clean的文件,当你执行make clean时,make会认为clean目标已经达成(因为它找到了同名文件),因此不会执行其下的rm命令。将clean声明为.PHONY后,make就会无视任何同名文件,每次都执行其命令。 - 性能优化:在一些复杂的
Makefile中,将伪目标声明为.PHONY可以告诉make它无需检查同名文件的状态,从而略微提升性能。 - 可读性与规范:它清晰地向阅读者表明,这个目标是一个动作,而不是一个文件。
常见误用与风险不要将实际的文件目标声明为 .PHONY。这样做会让 make 失去对文件时间戳的判断能力,导致该目标及其依赖链在每次执行 make 时都会被强制重新构建,从而破坏了 make 增量构建的核心优势。一个常见的最佳实践是提供一个 all 伪目标作为默认的构建入口,并将其放在 Makefile 的最开始。
.PHONY: all
all: program1 program2
# ... 后续是 program1 和 program2 的构建规则
这样,当用户直接运行 make 时,就会构建 all 所依赖的所有程序。
二、变量与赋值:让 Makefile 动起来
变量(在 GNU Make 的世界里有时也称作宏,Macro)是 Makefile 的核心组成部分,它们使得 Makefile 变得灵活、可配置和易于维护。
2.1 赋值操作符:=、:=、?= 和 +=
make 提供了四种主要的变量赋值操作符,它们的行为差异是理解 Makefile 的关键。
2.1.1 递归展开赋值 (=)
这是最常见的赋值方式。使用 = 定义的变量,其值的计算会被推迟到该变量被实际使用时才进行。这种方式被称为“递归展开”(Recursively Expanded)。
FOO = $(BAR)
BAR = $(BAZ)
BAZ = Hello
# 当执行 make 时...
all:
@echo $(FOO) # 输出 "Hello"
- 优点:可以引用在其后定义的变量,允许更灵活的顺序。
- 缺点:
- 性能:每次使用变量时都需要重新展开,对于复杂的
Makefile会有性能影响。 - 无限循环:可能导致无限递归展开的错误。
- 意外行为:如果变量值包含 shell 命令,可能会产生非预期的结果。
- 在上面的例子中,
target1- 和
target2- 输出的
VAR- 值(时间)将会不同,因为
$(shell date)- 在每次
$(VAR)- 被使用时都会被重新执行。
- 性能:每次使用变量时都需要重新展开,对于复杂的
VAR = $(shell date)
all: target1 target2
target1:
@echo "Target 1 VAR is: $(VAR)"
target2:
sleep 2
@echo "Target 2 VAR is: $(VAR)"
X = $(Y)
Y = $(X)
# 使用 $(X) 或 $(Y) 将导致 make 奔溃
2.1.2 简单展开赋值 (:=)
为了避免递归展开带来的问题,make 提供了 :=,即“简单展开”(Simply Expanded)。使用 := 定义的变量,其值会在定义时被立即计算并固定下来。
X := foo
Y := $(X) bar
X := later
# 当执行 make 时...
all:
@echo $(Y) # 输出 "foo bar",而不是 "later bar"
同样,对于上一节的 shell 示例,如果使用 :=,VAR 的值将在 Makefile 被读取时就确定下来,target1 和 target2 将输出相同的时间。最佳实践优先使用 := (简单展开赋值)。它能让你的 Makefile 行为更可预测,避免无限循环和不必要的重复计算,并且性能更好。只在确实需要延迟展开特性的少数情况下才使用 =。
2.1.3 条件赋值 (?=)
?= (Conditional Assignment) 的作用是:如果该变量尚未定义,则为其赋值;如果已经定义,则忽略此次赋值。
PLATFORM ?= "x86"
all:
@echo "Platform is $(PLATFORM)"
# 运行 `make` -> 输出 "Platform is x86"
# 运行 `make PLATFORM=arm` -> 输出 "Platform is arm"
这种方式非常适合为变量提供一个用户可以从命令行轻松覆盖的默认值。
2.1.4 追加赋值 (+=)
+= (Appending Assignment) 用于向一个已定义的变量追加内容。
OBJECTS = main.o utils.o
# ...
OBJECTS += logger.o
all:
@echo $(OBJECTS) # 输出 "main.o utils.o logger.o"
一个值得注意的细节是,+= 的行为依赖于被追加的变量最初是如何定义的:
- 如果变量是用
=定义的,+=也会延迟展开。 - 如果变量是用
:=定义的,+=会立即展开并追加。
2.2 变量的作用域与覆盖
make 中变量值的确定遵循一个清晰的优先级层次。
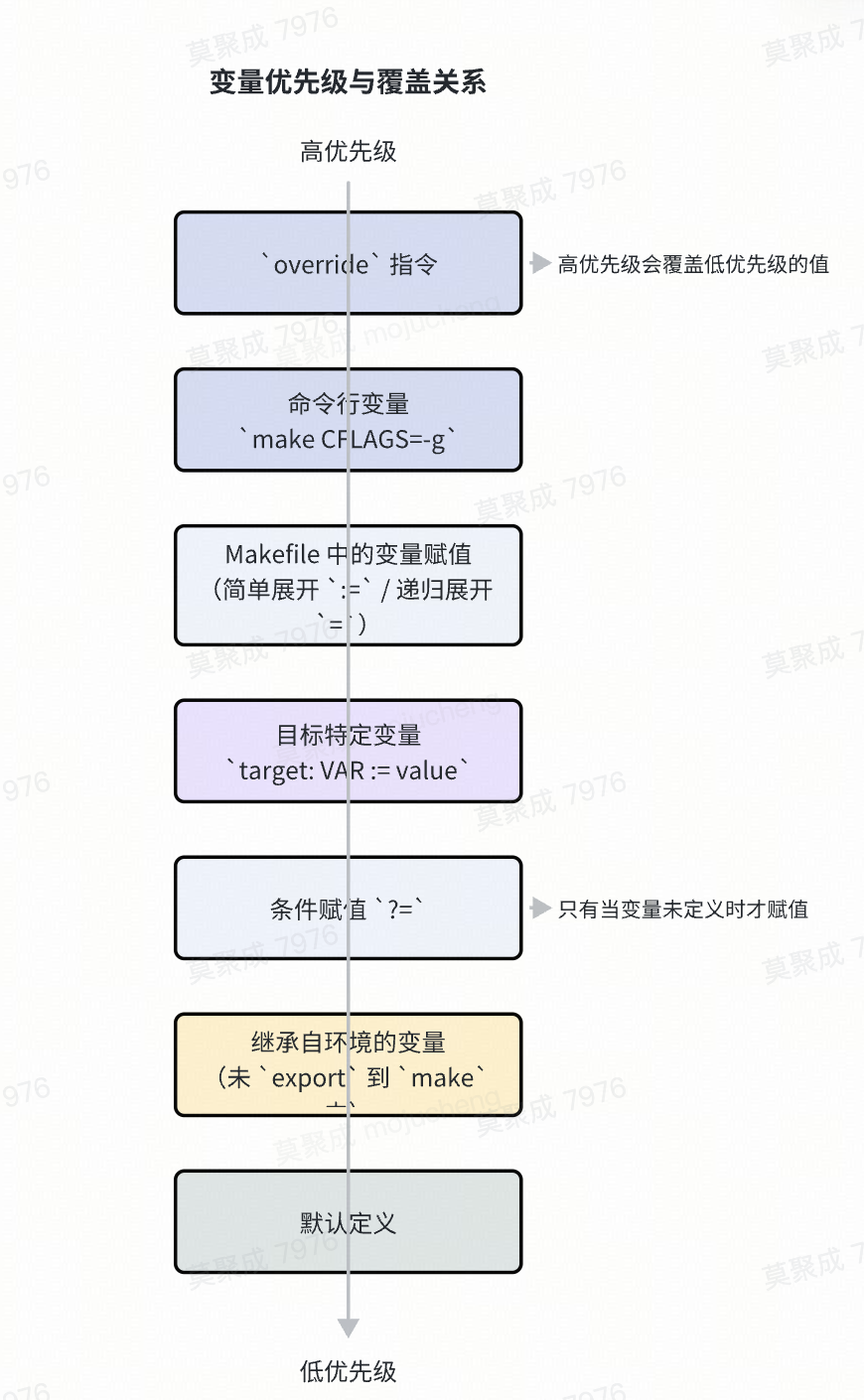
从高到低依次是:
override指令:使用override VAR := value定义的变量具有最高优先级,它会覆盖所有其他同名变量的定义,包括命令行传入的变量。- 命令行变量:通过命令行
make VAR=value传入的变量,优先级仅次于override。 - Makefile 中的赋值:在
Makefile文件内部通过=、:=等方式进行的赋值。 - 环境变量:从执行
make的 Shell 环境中继承的变量。前提是该环境变量没有被Makefile内部的赋值或命令行覆盖。 - 默认定义:
make内置的一些隐式规则和变量。
override 指令
当你希望 Makefile 内部的某个变量值不被命令行参数所覆盖时,可以使用 override。
override CFLAGS := -O2 -g
# 即使运行 `make CFLAGS="-Wall"`
# CFLAGS 的值依然是 "-O2 -g"
目标特定变量 (Target-specific Variables)
你还可以为特定的目标及其依赖链定义变量。
PROG = my_program
all: $(PROG)
$(PROG): CFLAGS := -g -O0 # 仅对 my_program 目标生效
$(PROG): $(PROG).o
gcc $(CFLAGS) -o $@ $^
$(PROG).o: CFLAGS := -Wall # 仅对 my_program.o 目标生效
$(PROG).o: $(PROG).c
gcc $(CFLAGS) -c -o $@ $<
这在需要为不同模块(如 release/debug 版本)设置不同编译选项时非常有用。
2.3 与环境的交互:export 和 unexport
默认情况下,Makefile 中定义的变量只在 make 进程内部有效,不会传递给它所调用的子进程(如 gcc、rm 等)。
export:将Makefile中的变量导出为环境变量,使其对所有子命令可见。- 运行
make- 将会看到子 Shell 也能读取到
MY_VAR- 。
unexport:阻止某个变量(通常是继承自外部环境的变量)被传递给子命令。
export MY_VAR = "some_value"
all:
@echo "Makefile sees: $(MY_VAR)"
@bash -c 'echo "Sub-shell sees: $$MY_VAR"'
2.4 其他高级变量技巧
define 多行变量
define 关键字允许你定义包含多行文本的变量,常用于定义一系列可复用的命令。
define compile_and_archive
@echo "Compiling $<..."
$(CC) $(CFLAGS) -c -o $@ $<
@echo "Archiving $@..."
ar rcs $(AR_TARGET) $@
endef
libfoo.a: foo.o bar.o
AR_TARGET = libfoo.a
foo.o: foo.c
$(compile_and_archive)
bar.o: bar.c
$(compile_and_archive)
origin 和 flavor 函数
$(origin VARIABLE):返回一个字符串,告诉你变量VARIABLE的来源。例如"environment"、"file"、"command line"、"default"、"undefined"等。这在调试复杂的Makefile时非常有用。$(flavor VARIABLE):返回变量的“风味”,即它是如何展开的。返回值是"undefined"、"recursive"(由=定义) 或"simple"(由:=定义)。
三、规则与模式:编写通用的构建逻辑
规则是 Makefile 的骨架。除了我们已经见过的普通规则,make 还提供了强大的模式规则,让你可以用更简洁的方式处理大量同类型的文件。
3.1 规则的种类
普通规则 (Explicit Rules)
这是我们最熟悉的规则,目标和依赖都是明确的文件名。
hello: main.o utils.o
gcc -o hello main.o utils.o
模式规则 (Pattern Rules)
模式规则使用 % 符号作为通配符,它能匹配任意非空字符串。这使得我们可以为一类文件定义一个通用的构建规则。
# 定义了如何从任意 .c 文件生成对应的 .o 文件
%.o: %.c
gcc -c $(CFLAGS) -o $@ $<
%.o:匹配任何以.o结尾的目标,例如main.o、utils.o。%.c:匹配与目标%.o中%所匹配部分相同的.c文件。例如,如果目标是main.o,%匹配main,那么依赖就是main.c。$@和$<:这些是“自动变量”,我们马上就会详细介绍。
静态模式规则 (Static Pattern Rules)
静态模式规则是模式规则的一种更精确的形式。它让你明确指定哪些目标适用该模式规则,而不是让 make 自行推导。
# 格式:
# targets...: target-pattern: prerequisite-patterns...
# commands
OBJECTS = foo.o bar.o baz.o
# 这条规则明确指出,只有当目标是 OBJECTS 列表中的一个时,
# 才应用 "%.o: %.c" 这个模式。
$(OBJECTS): %.o: %.c
gcc -c $(CFLAGS) -o $@ $<
- 优点:
- 更明确:比普通模式规则的意图更清晰,限制了规则的应用范围。
- 更高效:
make不需要搜索所有可能的模式,处理速度更快。 - 更灵活:依赖模式可以不包含
%,例如$(OBJECTS): %.o: %.c header.h,这会为所有.o文件添加一个共同的依赖header.h。
3.2 自动变量:规则的“魔术棒”
在规则的命令部分,使用自动变量可以让你的命令变得通用,无需硬编码文件名。
变量 | 含义 | 示例 ( target: dep1 dep2) |
$@ | 规则的完整目标名称。 | target |
$< | 第一个依赖的名称。 | dep1 |
$^ | 所有依赖的名称列表,以空格分隔,并去除重复项。 | dep1 dep2 |
$+ | 所有依赖的名称列表,以空格分隔,保留重复项。 | (如果依赖是 d1 d2 d1, 则为 d1 d2 d1) |
$? | 所有比目标更新的依赖的名称列表。 | (假设 dep2 比 target 新) dep2 |
* | 模式规则中 % 匹配的主干部分。 | (在 foo.o: foo.c 规则中为 foo) |
` | ` | 所有订单依赖(order-only prerequisites)的名称。我们下一节会讲。 |
将这些变量应用到我们的 C 项目 Makefile 中:
CC = gcc
CFLAGS = -Wall -g
SOURCES = main.c utils.c
OBJECTS = $(SOURCES:.c=.o) # 使用 patsubst 函数的简写
all: my_app
my_app: $(OBJECTS)
$(CC) $(CFLAGS) -o $@ $^ # 使用 $@ 代表 my_app, $^ 代表所有 .o 文件
# 使用模式规则,这条规则可以处理所有 .c -> .o 的转换
%.o: %.c
$(CC) $(CFLAGS) -c -o $@ $< # 使用 $@ 代表目标.o, $< 代表依赖.c
.PHONY: clean
clean:
rm -f my_app $(OBJECTS)
这个 Makefile 已经相当通用和简洁了。无论你增加多少个 .c 文件,只需要修改 SOURCES 变量即可,构建规则无需任何变动。
3.3 订单依赖 (Order-Only Prerequisites)
有时候,一个目标需要确保某个依赖存在,但当该依赖更新时,目标本身不需要重新构建。这种情况下的依赖就称为“订单依赖”。使用 | 来分隔普通依赖和订单依赖。
# 格式
target: normal-prereq | order-only-prereq
一个典型的应用场景是确保输出目录存在:
OBJDIR := obj
OBJS := $(addprefix $(OBJDIR)/, foo.o bar.o)
# 编译规则
# OBJS 的每个文件都依赖对应的 .c 文件,并且都“需要”OBJDIR 目录存在
$(OBJS): $(OBJDIR)/%.o: %.c | $(OBJDIR)
@echo "Compiling $< into $@"
@cp $< $@ # 简化演示,实际是编译命令
# 创建目录的规则
$(OBJDIR):
@echo "Creating directory $@"
@mkdir -p $@
.PHONY: clean
clean:
rm -rf $(OBJDIR)
- 当你第一次运行
make时,make发现obj目录不存在,它会先执行创建目录的命令。 - 然后,它会执行编译命令。
- 如果你再次运行
make,即使obj目录已经存在,make也不会因此重新编译所有.o文件。只有当对应的.c文件更新时,才会触发重新编译。
总结:普通依赖 vs. 订单依赖
- 普通依赖:如果依赖比目标新,目标需要重新构建。
- 订单依赖:仅用于决定执行顺序。依赖的更新不会直接触发目标的重新构建。
3.4 二次展开 (.SECONDEXPANSION)
这是一个高级特性,允许 Makefile 在读取完所有内容后,对依赖行进行第二次变量展开。这在你需要根据目标本身来动态生成依赖时非常有用。使用 .SECONDEXPANSION 声明后,你可以在依赖行中使用 $$* 或 $$@ 等形式。
.SECONDEXPANSION:
# 假设我们有一个规则,每个模块的输出依赖一个同名的配置文件
modules = moduleA moduleB
outputs = $(foreach m, $(modules), out/$(m).out)
# 第一次展开:make 读取时,将 $(outputs) 展开
$(outputs): $$(@D)/$$(*F).conf
@echo "Target: $@, Prerequisite: $^"
@touch $@
# 当 make 真正处理 out/moduleA.out 这个目标时,进行第二次展开:
# - $$@ -> out/moduleA.out
# - $$* -> out/moduleA (类似 $(basename $@))
# - $$(@D) -> out
# - $$(*F) -> moduleA
# 最终依赖被解析为:out/moduleA.conf
# 为了让例子能运行,我们创建依赖文件
all: $(outputs)
@echo "Done"
out/moduleA.conf:
@mkdir -p $(@D)
@echo "config for A" > $@
out/moduleB.conf:
@mkdir -p $(@D)
@echo "config for B" > $@
.PHONY: clean
clean:
rm -rf out
在这个例子中,每个输出文件 out/moduleA.out 的依赖是动态生成的 out/moduleA.conf。没有二次展开是很难做到这一点的。
四、目录与查找:管理你的源文件
当项目规模变大,源文件通常会分散在不同的子目录中。make 提供了一套机制来帮助你管理这些文件和目录。
4.1 vpath 与 VPATH:指定搜索路径
如果 make 在当前目录找不到规则所需的依赖文件,它会到你指定的搜索路径中去查找。
VPATH 变量
VPATH 是一个特殊变量,你可以将一系列以冒号(:)或空格分隔的目录赋值给它。
VPATH = src:../headers
# 当 make 需要 foo.c 时,它会依次查找:
# 1. ./foo.c
# 2. src/foo.c
# 3. ../headers/foo.c
缺点:VPATH 对所有类型的文件都生效,不够灵活。
vpath 指令
vpath 指令提供了更精细的控制,你可以为特定模式的文件指定搜索路径。它有三种形式:
vpath <pattern> <directories>为符合<pattern>模式的文件设置搜索路径<directories>。vpath <pattern>清除之前为<pattern>设置的搜索路径。vpath清除所有vpath设置的搜索路径。
# 为所有 .c 文件指定搜索路径为 src 目录
vpath %.c src
# 为所有 .h 文件指定搜索路径为 include 目录
vpath %.h include
示例:将源文件和目标文件分离一个常见的实践是将编译产生的中间文件(如 .o 文件)和最终产物放到一个独立的构建目录(如 build)中,以保持源码树的整洁。
SRCS := main.c utils.c
OBJS := $(SRCS:.c=.o)
BUILD_DIR := build
# 指定 .c 文件的搜索路径
vpath %.c src
# 指定所有目标文件都在 build 目录下
TARGET_OBJS := $(addprefix $(BUILD_DIR)/, $(OBJS))
all: $(BUILD_DIR)/my_app
# 链接规则:依赖都位于 build 目录
$(BUILD_DIR)/my_app: $(TARGET_OBJS)
gcc -o $@ $^
# 编译规则:目标在 build 目录,依赖在 src 目录
$(BUILD_DIR)/%.o: %.c
@mkdir -p $(@D) # $(@D) 是目标的目录部分
gcc -c -o $@ $<
.PHONY: clean
clean:
rm -rf $(BUILD_DIR)
在这个例子中,当你执行 make 时:
make需要构建build/main.o。- 它匹配到
$(BUILD_DIR)/%.o: %.c规则。 - 依赖是
main.c。make在当前目录找不到main.c,但通过vpath %.c src指令,它会在src/main.c找到文件。 - 自动变量
$<会被正确地设置为src/main.c。 - 命令
gcc -c -o build/main.o src/main.c被执行。
4.2 wildcard 函数:在 Makefile 中使用通配符
你可能习惯于在 Shell 中使用 * 来匹配文件,但在 Makefile 的变量赋值中,* 不会自动展开。你需要使用 wildcard 函数。
# 错误的方式
SOURCES = src/*.c
# $(SOURCES) 的值会是字符串 "src/*.c",而不是文件名列表
# 正确的方式
SOURCES = $(wildcard src/*.c)
# 假设 src 目录下有 main.c 和 utils.c
# $(SOURCES) 的值会是 "src/main.c src/utils.c"
这在源文件很多,不想手动一一列出时非常有用。
4.3 文件名处理函数
make 提供了一系列强大的函数,用于处理文件名和路径字符串。
函数 | 描述 | 示例 |
$(dir <names...>) | 提取每个文件名的目录部分。 | $(dir src/foo.c bar/baz.h) -> src/ ./ |
$(notdir <names...>) | 提取每个文件名的非目录部分(即文件名本身)。 | $(notdir src/foo.c bar/baz.h) -> foo.c baz.h |
$(suffix <names...>) | 提取每个文件名的后缀(最后一个 . 之后的部分)。 | $(suffix src/foo.c bar.baz.h) -> .c .h |
$(basename <names...>) | 提取每个文件名的无后缀部分。 | $(basename src/foo.c bar/baz.h) -> src/foo bar/baz |
$(addsuffix <suf>,<t>) | 为文本 <t> 中的每个单词添加后缀 <suf>。 | $(addsuffix .o, foo bar) -> foo.o bar.o |
$(addprefix <pre>,<t>) | 为文本 <t> 中的每个单词添加前缀 <pre>。 | $(addprefix src/, foo bar) -> src/foo src/bar |
$(join <list1>,<list2>) | 将 list1 和 list2 中的单词按顺序配对连接。 | $(join a b, .c .o) -> a.c b.o |
$(wildcard <pattern>) | 查找匹配 <pattern> 模式的实际文件并返回列表。 | $(wildcard *.c) -> main.c utils.c |
$(abspath <path>) | 将相对路径 <path> 转换为绝对路径。 | $(abspath ../src/foo) -> /path/to/project/src/foo |
$(realpath <path>) | 类似于 abspath,但会解析所有符号链接。 |
这些函数组合起来威力巨大。例如,从一组 .c 源文件自动生成 .o 目标文件列表:
SOURCES := $(wildcard src/*.c) # "src/main.c src/utils.c"
OBJS := $(patsubst %.c,%.o,$(SOURCES)) # "src/main.o src/utils.o"
(patsubst 是更通用的模式替换函数,我们将在下一章介绍。)另一个例子是自动创建所有目标文件需要的目录:
OBJS := build/app1/main.o build/app2/utils.o
DIRS := $(sort $(dir $(OBJS))) # "build/app1/ build/app2/"
# 某个地方使用订单依赖
all: | $(DIRS)
$(DIRS):
mkdir -p $@
这样,make 会在执行任何编译前,自动创建 build/app1 和 build/app2 目录。
五、条件与函数:Makefile 的编程能力
Makefile 不仅仅是规则的堆砌,它还具备了类似编程语言的条件判断、函数调用和循环等能力,这使得它能处理非常复杂的逻辑。
5.1 条件语句
make 的条件语句用于在 Makefile 被读取时,根据条件包含或忽略一部分 Makefile 内容。
ifeq / ifneq
用于判断两个字符串是否相等或不等。
# 格式一
ifeq (<arg1>, <arg2>)
# ... 如果 arg1 等于 arg2 ...
else
# ... 否则 ...
endif
# 格式二
ifeq '<arg1>' '<arg2>'
# ...
# 格式三
ifeq "<arg1>" "<arg2>"
# ...
一个常见的应用是根据平台类型设置不同的编译选项:
UNAME_S := $(shell uname -s)
ifeq ($(UNAME_S), Darwin) # macOS
LIBS += -framework CoreFoundation
else ifeq ($(UNAME_S), Linux)
LIBS += -lrt
endif
all:
@echo "Libs are: $(LIBS)"
注意条件语句是在 make 读取 Makefile 的阶段执行的,而不是在执行规则命令的阶段。这意味着你不能在命令中使用条件语句来控制 Shell 命令的执行流程(那种场景应该使用 Shell 的 if 语句)。
ifdef / ifndef
用于判断一个变量是否已经被定义。
# 如果 DEBUG 变量被定义了...
ifdef DEBUG
# 比如通过 `make DEBUG=1`
CFLAGS += -g -DDEBUG
else
# 否则...
CFLAGS += -O2
endif
5.2 文本处理函数
make 内置了大量用于处理字符串的函数,这在操作文件名列表时尤其有用。
函数 | 描述 |
$(subst <from>,<to>,<text>) | 文本替换。将 <text> 中的 <from> 替换为 <to>。 |
$(patsubst <p>,<r>,<t>) | 模式替换。将 <t> 中匹配模式 <p> 的单词替换为 <r>。% 作为通配符。 |
$(strip <string>) | 去掉 <string> 前后及中间多余的空白字符。 |
$(findstring <f>,<t>) | 在 <t> 中查找 <f>,如果找到则返回 <f>,否则返回空。 |
$(filter <p...>,<t>) | 过滤。返回 <t> 中匹配任一模式 <p...> 的单词。 |
$(filter-out <p...>,<t>) | 反向过滤。返回 <t> 中不匹配任何模式 <p...> 的单词。 |
$(sort <list>) | 对 <list> 中的单词按字母排序,并去除重复项。 |
$(word <n>,<text>) | 取第 <n> 个单词(从 1 开始)。 |
$(wordlist <s>,<e>,<t>) | 取从第 <s> 到第 <e> 个单词组成的列表。 |
$(words <text>) | 统计单词数量。 |
$(firstword <text>) | 取第一个单词。 |
$(lastword <text>) | 取最后一个单词。 |
patsubst 的威力patsubst 是最强大的文本处理函数之一。$(patsubst %.c, %.o, $(SOURCES)) 是其典型用法,但它还有一种更简洁的变量替换形式:
SOURCES := main.c utils.c logger.c
OBJECTS := $(SOURCES:.c=.o) # 等价于 $(patsubst %.c,%.o,$(SOURCES))
# OBJECTS 的值是 "main.o utils.o logger.o"
filter 和 filter-out 的应用从一个文件列表中分离出不同类型的文件:
FILES = foo.c foo.h bar.c bar.h baz.S
C_SOURCES = $(filter %.c, $(FILES)) # "foo.c bar.c"
ASM_SOURCES = $(filter %.S, $(FILES)) # "baz.S"
HEADERS = $(filter %.h, $(FILES)) # "foo.h bar.h"
5.3 foreach、call 与 eval:元编程三剑客
这三个函数提供了在 Makefile 中进行“元编程”的能力,即生成代码的代码。
$(foreach <var>,<list>,<text>)
foreach 函数用于循环遍历一个列表,并对每个元素应用一个表达式。
DIRS = src include doc
ALL_DIRS = $(foreach dir, $(DIRS), build/$(dir))
# ALL_DIRS 的值是 "build/src build/include build/doc"
它常用于根据一个列表生成一系列文件名或规则。
$(call <variable>,<param...>)
call 函数可以像调用普通函数一样“调用”一个 Makefile 变量,并将参数传递给它。在变量定义中,$(1)、$(2) 等会依次被替换为传递的参数。这对于定义可复用的、参数化的命令模板(类似 define,但更灵活)非常有用。
# 定义一个模板,用于下载和解压一个文件
# $(1): URL, $(2): local filename
DOWNLOAD_AND_EXTRACT = \
wget -O $(2) $(1); \
tar -xvf $(2)
# 使用 call 来生成具体命令
all:
$(call DOWNLOAD_AND_EXTRACT, http://foo.com/foo.tar.gz, foo.tar.gz)
$(call DOWNLOAD_AND_EXTRACT, http://bar.com/bar.tar.gz, bar.tar.gz)
$(eval <text>)
eval 函数是这三者中最强大的。它会把参数 <text> 的内容当作一段 Makefile 代码来执行,并立即解析。这允许你动态地生成和定义新的变量和规则。结合 foreach 和 eval,可以为一系列程序动态地生成它们各自的构建规则。
PROGRAMS = prog1 prog2
# 定义一个函数模板,用于生成一个程序的完整构建规则
# $(1): 程序名
define PROGRAM_template
# --- start of template for $(1) ---
# 规则:如何构建程序 $(1)
$(1): $$($(1)_OBJS)
$$(CC) -o $$@ $$^
# 变量:程序 $(1) 依赖的 .o 文件
$(1)_OBJS = $(1)_main.o $(1)_utils.o
# 规则:如何从 .c 生成 .o 文件 (静态模式规则)
$$($(1)_OBJS): %.o: %.c
$$(CC) -c -o $$@ $$<
# --- end of template for $(1) ---
endef
# 遍历所有程序,使用 eval 和 call 动态生成它们的构建规则
$(foreach prog,$(PROGRAMS),$(eval $(call PROGRAM_template,$(prog))))
# 注意模板中 $$ 的使用:
# - `$$@`, `$$^`, `$$<`: 防止在 eval 阶段被展开,保留给 `make` 执行规则时使用。
# - `$$($(1)_OBJS)`: 同样,这是为了在生成的规则中保留 `$(prog1_OBJS)` 这样的变量引用。
这段代码的最终效果,等同于在 Makefile 中手写了 prog1 和 prog2 两套完整的构建规则。eval 使得 Makefile 的自动化和模板化能力达到了一个新的高度。
5.4 shell、error 和 warning 函数
$(shell <command>): 执行一个 Shell 命令,并将其标准输出作为函数返回值。我们在uname -s的例子中已经见过它了。- 性能警示
- :滥用
$(shell)- 会严重拖慢
make- 的解析速度,因为它需要在读取
Makefile- 时派生子进程。尽量使用
make- 的内置函数来完成字符串处理,只在必要时(如获取环境信息)才使用
$(shell)- 。
$(error <text...>): 产生一条致命错误,并立即终止make的执行。错误信息就是<text...>。$(warning <text...>): 产生一条警告信息,但不会终止make的执行。
ifndef SOME_CONFIG
$(warning SOME_CONFIG is not defined, using default value.)
SOME_CONFIG := "default"
endif
ifeq ($(MY_VAR),)
$(error MY_VAR is not set. Please specify it.)
endif
六、并行与递归:驾驭大型项目
对于大型项目,构建过程可能非常耗时。make 提供了并行执行和递归调用的机制来应对这些挑战。
6.1 -j 并行构建
make 最激动人心的特性之一就是能够并行执行互不依赖的规则。只需在命令行中加入 -j 或 --jobs 选项。
make -j:make会尽可能多地启动并行任务(通常不推荐,可能耗尽系统资源)。make -jN:make会同时执行最多N个任务。一个常见的做法是N等于 CPU 的核心数或核心数的两倍。例如,make -j8。
并行原理:Jobservermake 通过一个名为 “jobserver” 的内部机制来协调并行任务。当 make -jN 启动时,它会创建一个包含 N 个“令牌”(token)的池子。每个子 make 进程或命令在执行前都需要从池子中获取一个令牌,执行完毕后再归还。这确保了同时运行的任务数量不会超过 N。编写支持并行的 Makefile要让 -j 正常工作,你的 Makefile 必须正确地声明了依赖关系。如果 targetA 依赖 targetB,但你没有在规则中写明,make 可能会并行地构建它们,导致 targetA 构建失败,因为它需要的文件 targetB 还没有生成。正确的依赖关系是并行构建的基石。
6.2 递归 make
当一个项目由多个相对独立的子模块组成时,一种常见的组织方式是在每个子模块目录中都放置一个 Makefile,然后由一个顶层的 Makefile 来统一调度。这种方式被称为“递归 make”。
# 顶层 Makefile
SUBDIRS = module1 module2
.PHONY: all $(SUBDIRS)
all: $(SUBDIRS)
$(SUBDIRS):
$(MAKE) -C $@
# 这段代码会依次进入 module1 和 module2 目录,并执行其中的 make 命令
# -C $@: 告诉 make 在执行前先切换到目标同名目录($@)
# $(MAKE) 变量
# 推荐总是使用 $(MAKE) 而不是直接写 `make`,因为 $(MAKE) 会自动传递一些重要的
# 命令行选项(如 -j)和 jobserver 的信息给子 make 进程,从而实现正确的全局并行构建。
递归 make 的问题尽管递归 make 广泛使用,但它也有一些固有的缺点:
- 全局视图缺失:顶层
make不知道子模块之间的精确依赖关系,它只能按顺序调用。这妨碍了全局最优的并行构建。 - 重复工作:不同的子模块可能会重复执行相同的任务。
- 难以传递变量:在顶层和子
Makefile之间传递和覆盖变量比较复杂。
现代的 Makefile 实践倾向于使用“非递归 make”的模式,即只有一个顶层的 Makefile,通过 include 其他 .mk 文件来组织整个项目。这种方式能让 make 拥有项目的完整依赖图,从而实现最高效的构建。我们将在下一章详细讨论。
6.3 增量构建与重建策略
make 的核心价值在于其增量构建能力:它只重新构建那些源文件被修改过的部分。
- 脏构建 (Dirty Build): 项目中有部分源文件被修改后的状态。
- 干净构建 (Clean Build): 项目从零开始,所有产物都被删除后的状态。
提供一个 clean 目标来支持干净构建是一个良好实践。
.PHONY: clean
clean:
rm -f $(TARGET) $(OBJECTS)
强制重建有时你需要强制重建某个目标,即使它的依赖没有变化(例如,当编译选项改变时)。有几种方法可以实现:
touch命令:touch一个源文件会更新它的时间戳,make就会认为它变动了,从而触发依赖它的目标的重建。- Stamp 文件: 创建一个“戳文件”来代表某个抽象操作的状态。
- 当
Makefile- 中
CFLAGS- 的定义改变时,
cflags.stamp- 的内容会变化,但
make- 无法直接感知。更好的做法是让 stamp 文件依赖
Makefile- 本身。当
Makefile- 文件被修改时,stamp 文件会重建,从而间接触发所有
.o- 文件的检查。虽然这不完美,但提供了一种思路。更精确的依赖管理需要更复杂的技巧(见进阶专题)。
# CFLAGS 变化时,需要全部重新编译
CFLAGS_STAMP = build/cflags.stamp
$(CFLAGS_STAMP): Makefile
@mkdir -p $(@D)
@echo "$(CFLAGS)" > $@
# 所有 .o 文件都依赖这个戳文件
$(OBJECTS): | $(CFLAGS_STAMP)
# ... 编译规则
七、include 与 .mk:工程化组织
随着 Makefile 变得越来越复杂,将所有逻辑都放在一个文件里会变得难以维护。include 指令允许你将 Makefile 拆分成多个模块化的片段。
# 主 Makefile
include build/config.mk
include build/golang.mk
include build/docker.mk
# ... 主 Makefile 中的顶层目标 ...
.PHONY: all
all: build test
build/config.mk: 可能包含版本号、输出目录等通用配置变量。build/golang.mk: 可能包含所有用于编译、测试 Go 代码的通用规则。build/docker.mk: 可能包含用于构建和推送 Docker 镜像的规则。
这种方式被称为“非递归 make”,是目前推荐的大型项目 Makefile 组织方式。
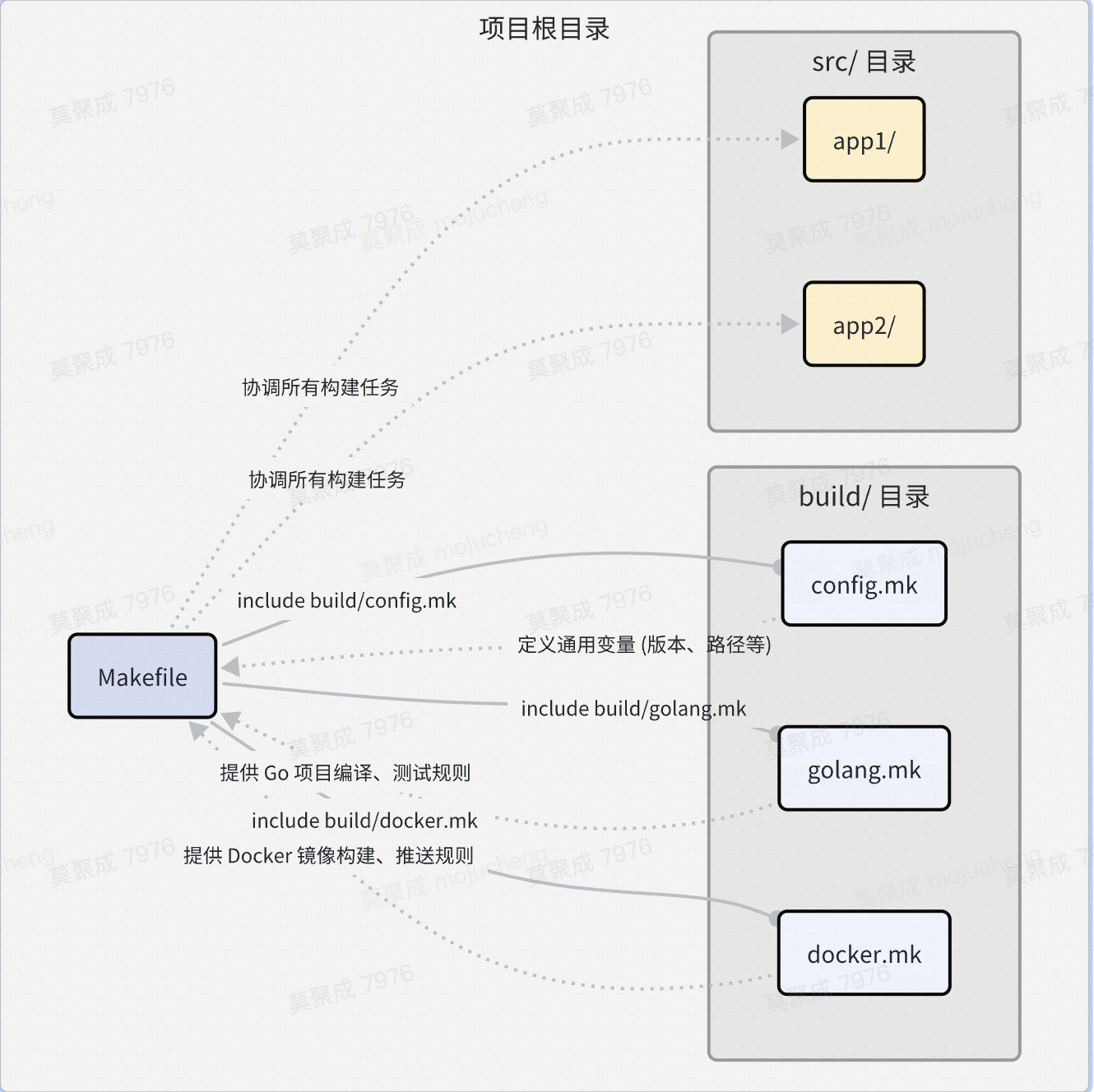
.mk 片段的组织与命名建议
- 按功能划分: 如
compiler.mk,tools.mk,deploy.mk。 - 按模块划分: 如
moduleA.mk,moduleB.mk。 - 约定目录: 将所有
.mk文件统一放在一个目录中,如build/make/。
include 的行为
- 如果
include指定的文件名不包含/,make会在一些标准位置查找(如/usr/local/include)。 - 使用
-I<dir>或--include-dir=<dir>命令行选项可以增加make查找.mk文件的目录。 sinclude(或-include):这是include的一个变体,如果文件不存在,它不会报错,而是静默地继续执行。这在包含可选的、或自动生成的配置文件时很有用。
八、调试与诊断
当 Makefile 不按预期工作时,make 提供了一些强大的工具来帮助你排查问题。
make -n或make --dry-run: 试运行。make会打印出它将要执行的所有命令,但不会实际执行它们。这是检查规则逻辑和命令是否正确的首选方法。make -p或make --print-data-base: 打印数据库。make会在执行前,打印出它内部维护的所有数据,包括所有变量的定义、所有规则(包括隐式规则)的完整信息。输出非常详细,但当你对某个变量的值或某条规则的来源感到困惑时,它就是终极的诊断工具。通常会结合-n使用,并且重定向到文件中分析:make -pn > make_debug.txt。make --debug[=<FLAGS>]: 开启调试输出。make会打印出详细的执行过程信息。make --debug=b: (basic) 提供基本的调试信息。make --debug=v: (verbose) 更详细的信息。make --debug=i: (implicit) 显示所有隐式规则的查找过程。make --debug=j: (jobs) 显示 jobserver 的详细信息。make --debug=a: (all) 开启所有调试标志。
make --warn-undefined-variables: 当Makefile中使用了未定义的变量时,make会给出警告。这是一个非常有用的选项,可以帮助你发现拼写错误或逻辑遗漏。
常见报错解析
*** missing separator. Stop.: 最常见的错误。几乎总是因为命令行的行首使用了空格而不是 Tab。*** No rule to make target 'xxx'. Stop.:make找不到构建目标xxx的任何规则,也找不到任何可以推导出的隐式规则。通常是文件名拼写错误,或者忘记为某个中间产物编写规则。No such file or directory: 这是由命令(如gcc,rm)报告的错误,而不是make本身。意味着make执行的命令试图访问一个不存在的文件。使用make -n检查命令中的文件名和路径是否正确。Circular xxx <- yyy dependency dropped.:make检测到了循环依赖(例如 A 依赖 B,B 又依赖 A)。你需要检查并修正你的依赖关系图。
九、实战案例
理论结合实践是最好的学习方式。下面通过三个不同层次的案例来展示 Makefile 在真实项目中的应用。
案例一:组织一个 C/C++ 小项目
这是一个典型的场景:管理源代码、头文件、编译、链接和测试。项目结构:
.
├── Makefile
├── include
│ └── utils.h
└── src
├── main.c
└── utils.c
Makefile 内容:
# 编译器和标志
CC := gcc
CXX := g++
CFLAGS := -Iinclude -Wall -g
LDFLAGS :=
# 自动发现源文件
SRCS := $(wildcard src/*.c)
OBJS := $(patsubst src/%.c, obj/%.o, $(SRCS))
# 目标可执行文件
TARGET := my_app
# ----------------- 规则 -----------------
.PHONY: all clean test
# 默认目标
all: $(TARGET)
# 链接规则
$(TARGET): $(OBJS)
$(CC) $(LDFLAGS) -o $@ $^
# 编译规则 (静态模式规则)
# 将所有 .o 文件放在 obj 目录下
# 依赖于对应的 .c 文件,并且需要确保 obj 目录存在
obj/%.o: src/%.c | obj
$(CC) $(CFLAGS) -c -o $@ $<
# 订单依赖:创建 obj 目录
obj:
@mkdir -p $@
# 清理规则
clean:
@echo "Cleaning up..."
@rm -rf $(TARGET) obj
# 一个简单的测试目标
test: $(TARGET)
@echo "Running tests..."
./$(TARGET) --test
解读:
- 自动化:通过
wildcard和patsubst自动处理文件的增删,无需手动维护文件列表。 - 源码与构建分离:通过将
.o文件输出到obj目录,保持了源码目录的干净。 - 订单依赖:使用
obj订单依赖来自动创建构建目录,且只创建一次。 - 伪目标:提供了
all、clean、test等清晰的入口点。
案例二:在多语言项目中协调任务
Makefile 不仅仅是编译工具,它也是一个优秀的任务运行器(Task Runner)。在包含 Go、JavaScript、Python 等多种语言的现代项目中,make 可以用来统一所有开发任务的入口。项目结构:
.
├── Makefile
├── api/ # Go 后端服务
│ ├── go.mod
│ └── main.go
└── web/ # 前端应用
├── package.json
└── src/
Makefile 内容:
.PHONY: all build-backend build-frontend test run-backend run-frontend clean
# --- 全局任务 ---
all: build-backend build-frontend
# --- 后端任务 (Go) ---
build-backend:
@echo "Building backend..."
@cd api && go build -o ../bin/server .
run-backend:
@echo "Running backend server..."
@./bin/server
# --- 前端任务 (Node.js/npm) ---
# 使用 .npm-install 戳文件来避免每次都执行 npm install
.npm-install: web/package.json
@cd web && npm install
@touch .npm-install
build-frontend: .npm-install
@echo "Building frontend..."
@cd web && npm run build
run-frontend: .npm-install
@echo "Running frontend dev server..."
@cd web && npm run dev
# --- 其他任务 ---
test:
@echo "Running backend tests..."
@cd api && go test ./...
@echo "Running frontend tests..."
@cd web && npm test
clean:
@echo "Cleaning up..."
@rm -rf bin/ .npm-install
@cd web && rm -rf node_modules build
解读:
- 统一入口:开发者无需记住
go build、npm run build等各种命令,只需执行make build-backend或make build-frontend。 - 任务依赖:通过
build-frontend: .npm-install这样的依赖,make能确保在构建前已经安装了npm依赖。 - 增量操作:使用
.npm-install这样的“戳文件”(Stamp File),只有当web/package.json更新时,才会重新执行npm install,极大地提高了效率。
案例三:采用模式规则与自动变量进行通用构建
这个案例展示了如何编写一个可复用的 .mk 文件,用于处理任何 C 项目的通用构建逻辑。common.mk 文件:
# common.mk - 可复用的 C 项目构建逻辑
#
# 需要在包含此文件的 Makefile 中定义以下变量:
# TARGET: 最终可执行文件名
# SRCS: 源文件列表 (e.g., $(wildcard *.c))
ifndef TARGET
$(error TARGET is not defined)
endif
ifndef SRCS
$(error SRCS is not defined)
endif
# 自动变量
OBJ_DIR := obj
OBJS := $(patsubst %.c, $(OBJ_DIR)/%.o, $(notdir $(SRCS)))
DEPS := $(OBJS:.o=.d) # 依赖文件
# --- 编译与链接标志 ---
CFLAGS ?= -g -Wall
CPPFLAGS ?= -I.
LDFLAGS ?=
# --- 核心规则 ---
.PHONY: all clean
all: $(TARGET)
$(TARGET): $(OBJS)
@echo "Linking $@..."
$(CC) $(LDFLAGS) -o $@ $^
# 编译 .c 文件并自动生成依赖 .d 文件
$(OBJ_DIR)/%.o: %.c
@mkdir -p $(@D)
@echo "Compiling $<..."
$(CC) $(CFLAGS) $(CPPFLAGS) -MMD -MP -c -o $@ $<
# 清理规则
clean:
@rm -rf $(TARGET) $(OBJ_DIR)
# 包含所有自动生成的依赖文件
-include $(DEPS)
在一个具体项目中使用 common.mk:
# project/Makefile
TARGET := my_program
SRCS := $(wildcard src/*.c)
# 指定头文件搜索路径
CPPFLAGS += -Iinclude
# 包含通用构建逻辑
include ../build/common.mk
解读:
- 模块化与复用:
common.mk文件可以被多个项目复用。 - 自动依赖生成:
gcc的-MMD -MP选项会自动为每个源文件生成一个.d依赖文件,其中记录了它include了哪些头文件。 -include $(DEPS):make会将这些.d文件包含进来。这意味着,当你修改一个头文件时,make会知道所有依赖该头文件的.c文件都需要被重新编译。这实现了精准的增量构建。
十、进阶专题
10.1 eval 与 call 的组合应用:动态生成规则
eval 和 call 的组合是 Makefile 元编程的巅峰。它们可以用于创建高度可定制和可扩展的构建系统,例如为不同平台、不同架构生成各自独立的构建规则集。想象一个场景,你需要为 arm 和 x86 两个架构编译同一套代码,但它们的编译器和编译选项都不同。
# 定义一个规则模板
# $(1): 架构 (arm, x86)
define ARCH_RULES
TARGET_$(1) := my_app_$(1)
CC_$(1) := $(1)-linux-gcc
OBJS_$(1) := $(patsubst %.c, obj_$(1)/%.o, $(SRCS))
all: $$(TARGET_$(1)) # 注意 $$
$$(TARGET_$(1)): $$ (OBJS_$(1))
$$(CC_$(1)) -o $$@ $$^
obj_$(1)/%.o: src/%.c
@mkdir -p $$(@D)
$$(CC_$(1)) -c -o $$@ $$<
endef
# --- 主逻辑 ---
SRCS := main.c utils.c
ARCHS := arm x86
# 遍历所有架构,使用 eval 和 call 动态生成所有规则和变量
$(foreach arch, $(ARCHS), $(eval $(call ARCH_RULES, $(arch))))
这段代码执行后,make 的内部数据库中会同时存在 my_app_arm 和 my_app_x86 两套完全独立的构建规则链,拥有各自的编译器、目标文件和输出目录。
10.2 精准依赖与自动依赖生成
我们已经在案例三中看到了使用 gcc -MMD 来自动生成头文件依赖的方法。这是编写健壮 Makefile 的关键一步,因为它避免了手动维护头文件依赖的巨大负担。让我们更深入地理解这个过程:
gcc -MMD -c -o foo.o foo.c:这个命令除了会生成foo.o,还会创建一个foo.d文件,其内容可能如下:-include $(DEPS):make在读取主Makefile时,会尝试包含所有.d文件。-include的作用是,如果文件不存在(比如第一次干净构建时),make不会报错。- 工作流:
- 第一次构建:
.d文件不存在,make跳过它们。编译规则被执行,生成了.o和.d文件。 - 第二次构建:
make读取了所有.d文件,知道了foo.o还依赖my_header.h。 - 修改
my_header.h后再次构建:make检测到my_header.h比foo.o更新,因此会重新编译foo.o。
- 第一次构建:
foo.o: foo.c /usr/include/stdio.h my_header.h
这种机制是实现真正可靠的增量构建的核心。
10.3 跨平台 Makefile 的 Shell 差异
编写可移植的 Makefile 时,最大的挑战之一是不同平台(Linux, macOS, Windows)下 Shell 命令的差异。
rm: Linux/macOS 下的rm -rf在 Windows (CMD/PowerShell) 下不存在。- 路径分隔符: POSIX 系统使用
/,Windows 使用\。 - 环境变量: 设置环境变量的语法不同。
解决方案:
- 使用
make内置函数:尽可能使用$(dir),$(notdir)等make函数处理路径,而不是dirname,basename等 Shell 命令。 - 定义平台无关的变量:
- 使用
$(shell)时要格外小心:$(shell ...)执行的命令直接受当前 Shell 环境影响。如果必须使用,请确保其在所有目标平台上都可用,或为其提供替代方案。 - 避免复杂的 Shell 脚本:不要在
Makefile的命令中嵌入复杂的、多行的 Shell 脚本。如果逻辑复杂,将其移到一个独立的脚本文件 (.sh,.py) 中,然后在Makefile里调用这个脚本。这能更好地隔离平台差异。
ifeq ($(OS), Windows_NT)
RM := del /Q
MKDIR_P := mkdir
else
RM := rm -f
MKDIR_P := mkdir -p
endif
clean:
$(RM) $(TARGET)
十一、练习与参考答案
入门练习
- 任务:为一个包含
main.c和math_utils.c(提供了add函数) 以及math_utils.h的项目编写一个Makefile。- 目标是生成一个名为
calculator的可执行文件。 - 提供一个
clean目标来删除所有生成的文件 (.o和calculator)。 - 尝试手动编写所有规则,不要使用模式规则。
- 目标是生成一个名为
- 答案思路:
.PHONY: all clean
all: calculator
calculator: main.o math_utils.o
gcc -o calculator main.o math_utils.o
main.o: main.c math_utils.h
gcc -c main.c
math_utils.o: math_utils.c math_utils.h
gcc -c math_utils.c
clean:
rm -f calculator *.o
进阶练习
- 任务:重构入门练习的
Makefile。- 使用模式规则 (
%.o: %.c) 来简化编译部分。 - 使用变量来管理源文件、目标文件和编译器。
- 为
gcc添加-Wall和-g编译选项。
- 使用模式规则 (
- 答案思路:
CC = gcc
CFLAGS = -Wall -g
SRCS = main.c math_utils.c
OBJS = $(SRCS:.c=.o)
TARGET = calculator
.PHONY: all clean
all: $(TARGET)
$(TARGET): $(OBJS)
$(CC) -o $@ $^
%.o: %.c
$(CC) $(CFLAGS) -c -o $@ $<
# 精确依赖
main.o: math_utils.h
math_utils.o: math_utils.h
clean:
rm -f $(TARGET) $(OBJS)
挑战练习
- 任务:为你的团队设计一个可复用的
project.mk模板。- 该模板应能自动查找
src目录下的所有.c和.cpp文件。 - 所有中间文件 (
.o,.d) 都应输出到build目录。 - 支持通过
make BUILD=debug或make BUILD=release来切换调试和发布模式的编译选项。 - 实现自动依赖生成(头文件依赖)。
- 该模板应能自动查找
- 答案思路 (
project.mk):
# --- 默认配置 ---
BUILD ?= debug
SRC_DIRS ?= src
BUILD_DIR ?= build
# --- 查找源文件 ---
CSOURCES := $(foreach dir,$(SRC_DIRS),$(wildcard $(dir)/*.c))
CXXSOURCES := $(foreach dir,$(SRC_DIRS),$(wildcard $(dir)/*.cpp))
# --- 生成目标文件列表 ---
OBJS := $(patsubst %.c,$(BUILD_DIR)/%.o,$(notdir $(CSOURCES)))
OBJS += $(patsubst %.cpp,$(BUILD_DIR)/%.o,$(notdir $(CXXSOURCES)))
DEPS := $(OBJS:.o=.d)
# --- 设置编译选项 ---
CPPFLAGS += $(foreach dir,$(SRC_DIRS),-I$(dir))
ifeq ($(BUILD), release)
CFLAGS ?= -O2 -DNDEBUG
CXXFLAGS ?= -O2 -DNDEBUG
else
CFLAGS ?= -g -Wall
CXXFLAGS ?= -g -Wall
endif
# --- 规则 ---
.PHONY: all clean
all: $(TARGET)
$(TARGET): $(OBJS)
$(CXX) $(LDFLAGS) -o $@ $^
$(BUILD_DIR)/%.o: %.c
@mkdir -p $(@D)
$(CC) $(CFLAGS) $(CPPFLAGS) -MMD -MP -c -o $@ $<
$(BUILD_DIR)/%.o: %.cpp
@mkdir -p $(@D)
$(CXX) $(CXXFLAGS) $(CPPFLAGS) -MMD -MP -c -o $@ $<
clean:
@rm -rf $(BUILD_DIR) $(TARGET)
-include $(DEPS)
附录:速查表
常用命令行选项
make: 执行第一个目标。make <target>: 执行指定目标。make -j<N>: 最多N个任务并行执行。make -n: 试运行,只打印命令不执行。make -p: 打印内部数据库。make -C <dir>: 在执行前切换到<dir>目录。make -f <file>: 使用<file>作为Makefile文件。make -k: 遇到错误时,继续执行其他不相关的规则。make --warn-undefined-variables: 对未定义变量发出警告。
常用自动变量
$@: 完整目标名。$<: 第一个依赖名。$^: 所有依赖名列表(去重)。$?: 所有比目标新的依赖名列表。*: 模式规则中的主干部分。
核心函数
$(wildcard pattern): 查找匹配的文件。$(patsubst pattern,replacement,text): 模式替换。$(subst from,to,text): 字符串替换。$(strip string): 去除空白。$(filter pattern...,text): 过滤。$(foreach var,list,text): 循环。$(shell command): 执行 Shell 命令。$(eval text): 将文本作为Makefile片段执行。