Hello-Agents阅读笔记
1.Agent简介
1.1 定义
在探索任何一个复杂概念时,我们最好从一个简洁的定义开始。在人工智能领域,智能体被定义为任何能够通过传感器(Sensors)感知其所处环境(Environment),并自主地通过执行器(Actuators)采取行动(Action)以达成特定目标的实体。
1.2 Agent的任务环境定义
要理解智能体的运作,我们必须先理解它所处的任务环境。在人工智能领域,通常使用PEAS 模型来精确描述一个任务环境,即分析其性能度量(Performance)、环境(Environment)、执行器(Actuators)和传感器(Sensors) 。以上文提到的智能旅行助手为例,下表 1.2 展示了如何运用 PEAS 模型对其任务环境进行规约。

1.3 Agent的运行机制
在定义了智能体所处的任务环境后,我们来探讨其核心的运行机制。智能体并非一次性完成任务,而是通过一个持续的循环与环境进行交互,这个核心机制被称为 智能体循环 (Agent Loop)。如图 1.5 所示,该循环描述了智能体与环境之间的动态交互过程,构成了其自主行为的基础。
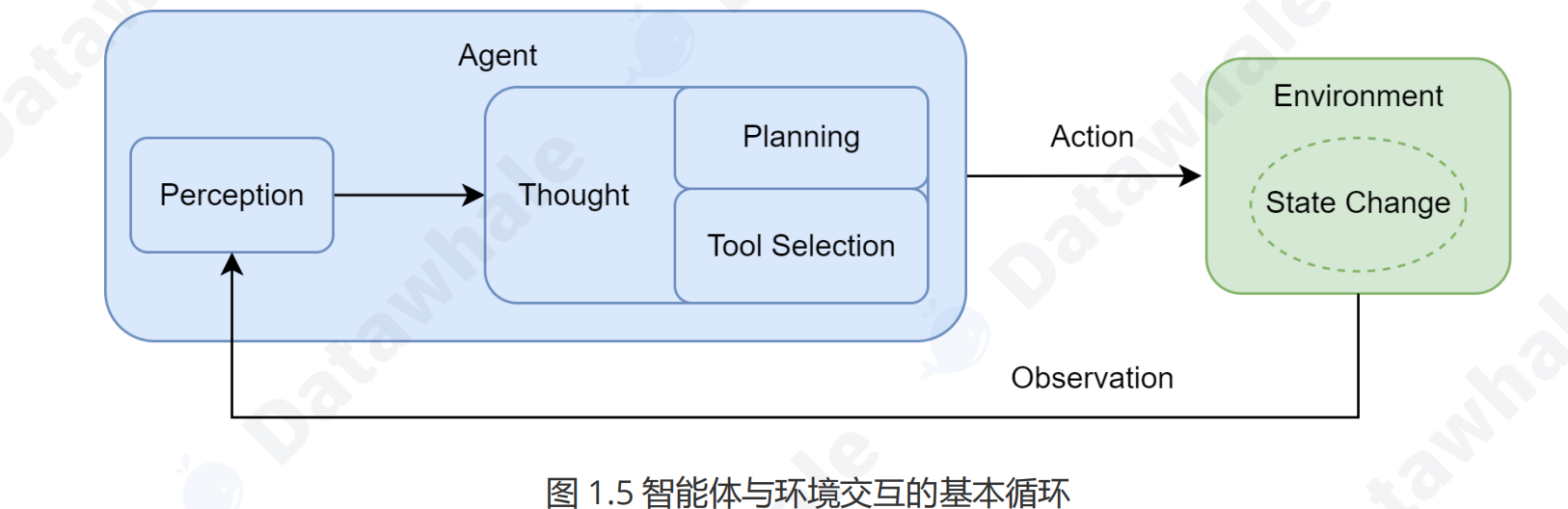
这个循环主要包含以下几个相互关联的阶段:
1. 感知 (Perception):这是循环的起点。智能体通过其传感器(例如,API 的监听端口、用户输入接口)接收来自环境的输入信息。这些信息,即观察 (Observation),既可以是用户的初始指令,也可以是上一步行动所导致的环境状态变化反馈。
2. 思考 (Thought):接收到观察信息后,智能体进入其核心决策阶段。对于 LLM 智能体而言,这通常是由大语言模型驱动的内部推理过程。如图所示,“思考”阶段可进一步细分为两个关键环节:
- 规划 (Planning):智能体基于当前的观察和其内部记忆,更新对任务和环境的理解,并制定或调整一个行动计划。这可能涉及将复杂目标分解为一系列更具体的子任务。
- 工具选择 (Tool Selection):根据当前计划,智能体从其可用的工具库中,选择最适合执行下一步骤的工具,并确定调用该工具所需的具体参数。
3. 行动 (Action):决策完成后,智能体通过其执行器(Actuators)执行具体的行动。这通常表现为调用一个选定的工具(如代码解释器、搜索引擎 API),从而对环境施加影响,意图改变环境的状态。
行动并非循环的终点。智能体的行动会引起环境 (Environment) 的状态变化 (State Change),环境随即会产生一个新的观察 (Observation) 作为结果反馈。这个新的观察又会在下一轮循环中被智能体的感知系统捕获,形成一个持续的“感知-思考-行动-观察”的闭环。智能体正是通过不断重复这一循环,逐步推进任务,从初始状态向目标状态演进。
1.4 智能体的感知与行动
在工程实践中,为了让 LLM 能够有效驱动这个循环,我们需要一套明确的交互协议 (Interaction Protocol)来规范其与环境之间的信息交换。
在许多现代智能体框架中,这一协议体现在对智能体每一次输出的结构化定义上。智能体的输出不再是单一的自然语言回复,而是一段遵循特定格式的文本,其中明确地展示了其内部的推理过程与最终决策。这个结构通常包含两个核心部分:
Thought (思考):这是智能体内部决策的“快照”。它以自然语言形式阐述了智能体如何分析当前情境、回顾上一步的观察结果、进行自我反思与问题分解,并最终规划出下一步的具体行动。
Action (行动):这是智能体基于思考后,决定对环境施加的具体操作,通常以函数调用的形式表示。
例如,一个正在规划旅行的智能体可能会生成如下格式化的输出:
Thought: 用户想知道北京的天气。我需要调用天气查询工具。
Action: get_weather("北京")这里的 Action 字段构成了对外部世界的指令。一个外部的解析器 (Parser) 会捕捉到这个指令,并调用相应的 get_weather 函数。
行动执行后,环境会返回一个结果。例如, get_weather 函数可能返回一个包含详细天气数据的 JSON 对象。然而,原始的机器可读数据(如 JSON)通常包含 LLM 无需关注的冗余信息,且格式不符合其自然语言处理的习惯。
因此,感知系统的一个重要职责就是扮演传感器的角色:将这个原始输出处理并封装成一段简洁、清晰的自然语言文本,即观察。
Observation: 北京当前天气为晴, 25摄氏度,微风。这段 Observation 文本会被反馈给智能体,作为下一轮循环的主要输入信息,供其进行新一轮的 Thought和 Action 。
综上所述,通过这个由 Thought、Action、Observation 构成的严谨循环,LLM 智能体得以将内部的语言推理能力,与外部环境的真实信息和工具操作能力有效地结合起来。
2.Agent的发展历程
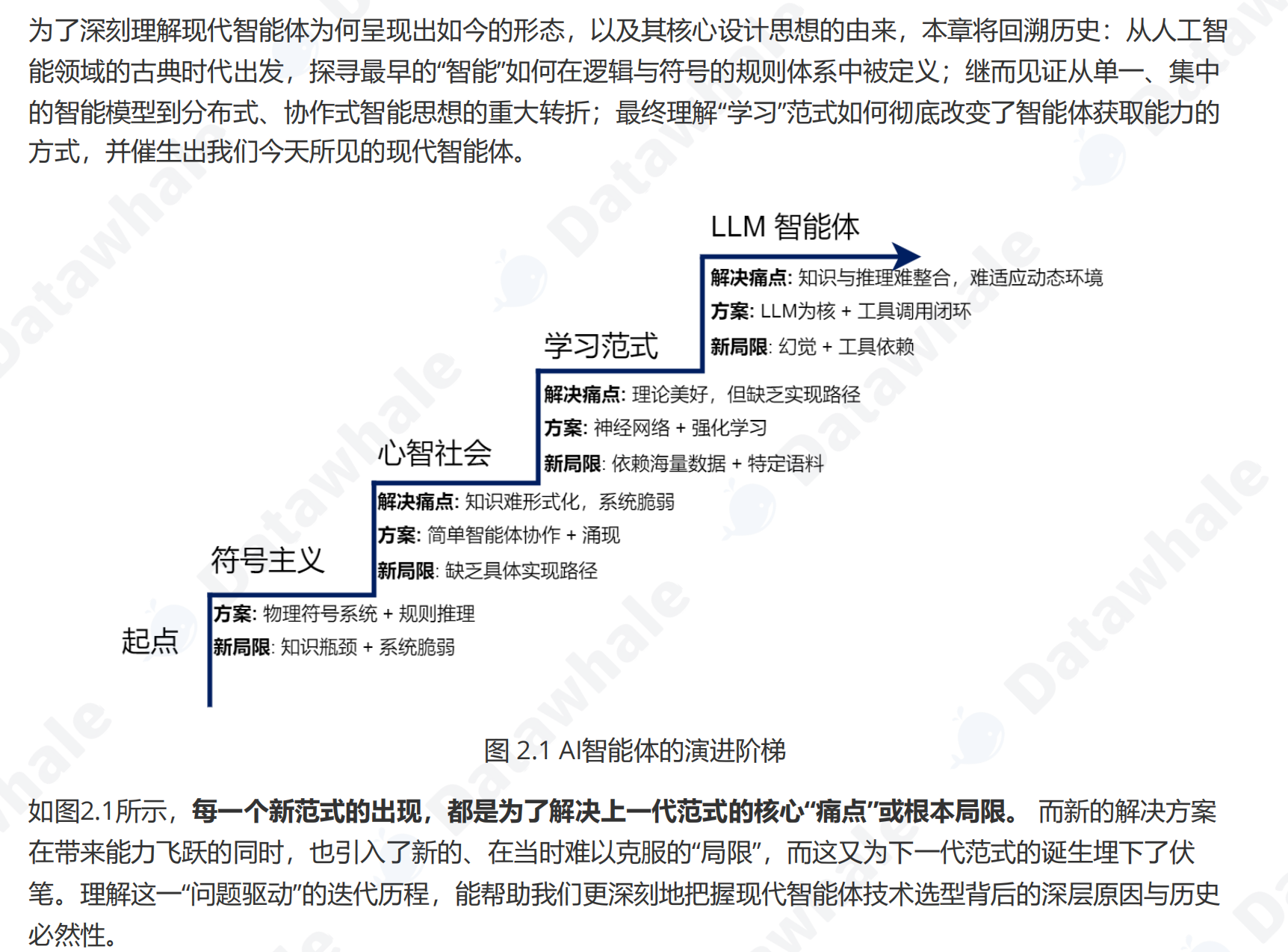
至此,智能体发展的历史长河中,几大关键的技术拼图已经悉数登场:符号主义提供了逻辑推理的框架,联结主义和强化学习提供了学习与决策的能力,而大型语言模型则提供了前所未有的、通过预训练获得的世界知识和通用推理能力。下一节,我们将看到这些技术是如何在现代智能体的设计中融为一体的。
2.1 基于强化学习的智能体
联结主义主要解决了感知问题(例如,“这张图片里有什么?”),但智能体更核心的任务是进行决策(例如,“在这种情况下,我应该做什么?”)。强化学习(Reinforcement Learning, RL)正是专注于解决序贯决策问题的学习范式。它并非直接从标注好的静态数据集中学习,而是通过智能体与环境的直接交互,在“试错”中学习如何最大化其长期收益。
以AlphaGo为例,其核心的自我对弈学习过程便是强化学习的经典体现[9]。在这个过程中,AlphaGo(智能体)通过观察棋盘的当前布局(环境状态),决定下一步棋的落子位置(行动)。一局棋结束后,根据胜负结果,它会收到一个明确的信号:赢了就是正向奖励,输了则是负向奖励。通过数百万次这样的自我对弈,AlphaGo不断调整其内部策略,逐渐学会了在何种棋局下选择何种行动,最有可能导向最终的胜利。这个过程完全是自主的,不依赖于人类棋谱的直接指导。
这种通过与环境互动、根据反馈信号来优化自身行为的学习机制,就是强化学习的核心框架。下面我们将详细拆解其基本构成要素和工作模式。强化学习的框架可以用几个核心要素来描述:
- 智能体(Agent):学习者和决策者。在AlphaGo的例子中,就是其决策程序。环境(Environment):智能体外部的一切,是智能体与之交互的对象。对AlphaGo而言,就是围棋的规则和对手。
- 状态(State, S):对环境在某一时刻的特定描述,是智能体做出决策的依据。例如,棋盘上所有棋子的当前位置。
- 行动(Action, A):智能体根据当前状态所能采取的操作。例如,在棋盘的某个合法位置上落下一子。
奖励(Reward, R):环境在智能体执行一个行动后,反馈给智能体的一个标量信号,用于评价该行动在特定状态下的好坏。例如,在一局棋结束后,胜利获得+1的奖励,失败获得-1的奖励。基于上述核心要素,强化学习智能体在一个“感知-行动-学习”的闭环中持续迭代,其工作模式如图2.8所示。
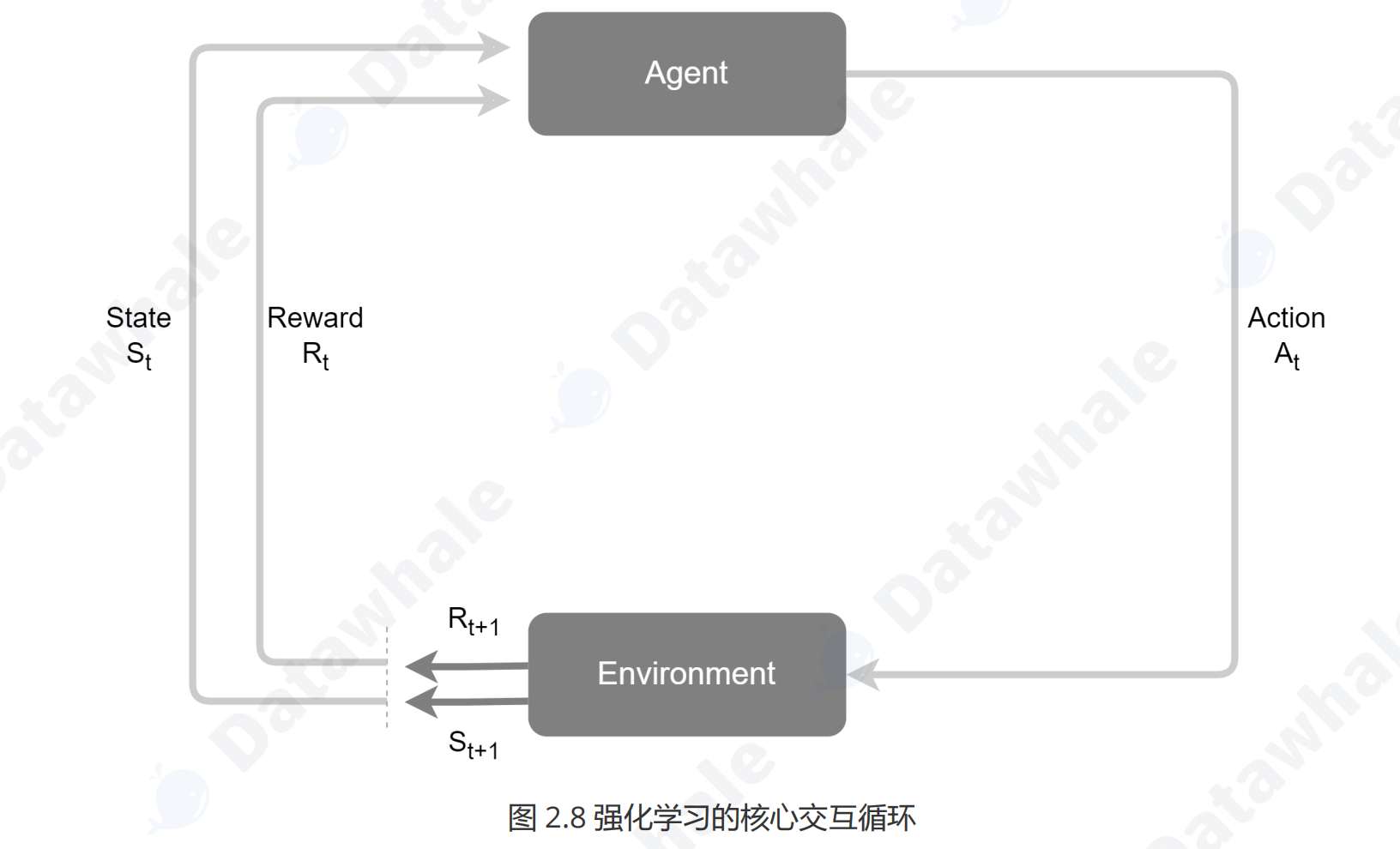
这个循环的具体步骤如下:
1. 在时间步t,智能体观察到环境的当前状态 。
2. 基于状态 ,智能体根据其内部的策略(Policy, π)选择一个行动 并执行它。策略本质上是一个式。
3. 环境接收到行动 后,会转移到一个新的状态。
4. 同时,环境会反馈给智能体一个即时奖励。
5. 智能体利用这个反馈(新状态和奖励)来更新和优化其内部策略,以便在未来做出更好的决策。这个更新过程就是学习。
智能体的学习目标,并非最大化某一个时间步的即时奖励,而是最大化从当前时刻开始到未来的累积奖励(Cumulative Reward),也称为回报(Return)。这意味着智能体需要具备“远见”,有时为了获得未来更大的奖励,需要牺牲当前的即时奖励(例如,围棋中的“弃子”策略)。通过在上述循环中不断探索、收集反馈并优化策略,智能体最终能够学会在复杂动态环境中进行自主决策和长期规划。
2.2 基于大语言模型的智能体
随着大型语言模型技术的飞速发展,以LLM为核心的智能体已成为人工智能领域的新范式。它不仅能够理解和生成人类语言,更重要的是,能够通过与环境的交互,自主地感知、规划、决策和执行任务。
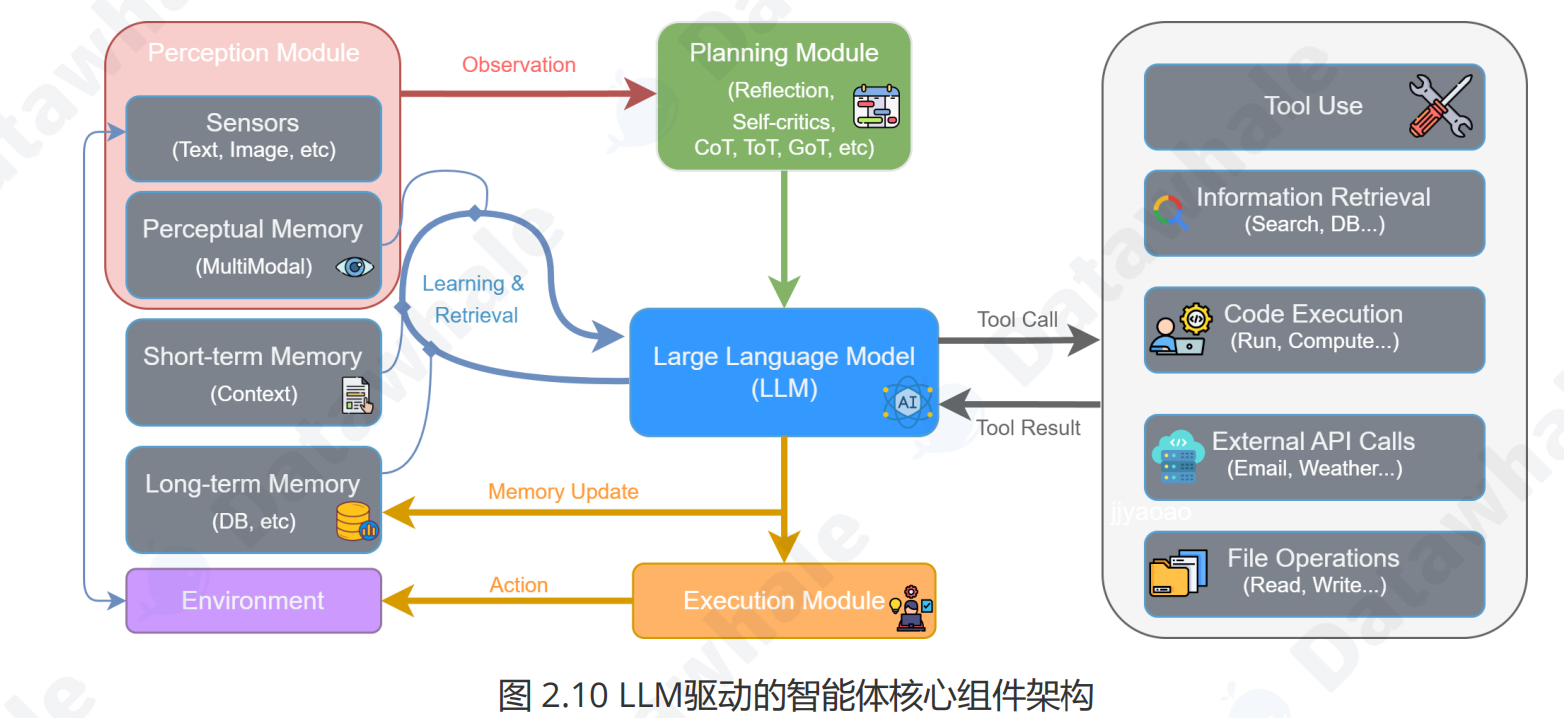
如第一章所述,智能体与环境的交互可以被抽象为一个核心循环。LLM驱动的智能体通过一个由多个模块协同工作的、持续迭代的闭环流程来完成任务。该流程遵循图2.10所示的架构,具体步骤如下:
1. 感知 (Perception) :流程始于感知模块 (Perception Module)。它通过传感器从外部环境(Environment) 接收原始输入,形成观察 (Observation)。这些观察信息(如用户指令、API返回的数据或环境状态的变化)是智能体决策的起点,处理后将被传递给思考阶段。
2. 思考 (Thought) :这是智能体的认知核心,对应图中的规划模块 (Planning Module) 和大型语言模型(LLM) 的协同工作。
- 规划与分解:首先,规划模块接收观察信息,进行高级策略制定。它通过反思 (Reflection) 和自我批判 (Self-criticism) 等机制,将宏观目标分解为更具体、可执行的步骤。
- 推理与决策:随后,作为中枢的LLM 接收来自规划模块的指令,并与记忆模块 (Memory) 交互以整合历史信息。LLM进行深度推理,最终决策出下一步要执行的具体操作,这通常表现为一个工具调用 (Tool Call)。
3. 行动 (Action) :决策完成后,便进入行动阶段,由执行模块 (Execution Module) 负责。LLM生成的工具调用指令被发送到执行模块。该模块解析指令,从工具箱 (Tool Use) 中选择并调用合适的工具(如代码执行器、搜索引擎、API等)来与环境交互或执行任务。这个与环境的实际交互就是智能体的行动 (Action)。4. 观察 (Observation) 与循环 :行动会改变环境的状态,并产生结果。工具执行后会返回一个工具结果 (Tool Result) 给LLM,这构成了对行动效果的直接反馈。同时,智能体的行动改变了环境,从而产生了一个全新的环境状态。这个“工具结果”和“新的环境状态”共同构成了一轮全新的观察 (Observation)。这个新的观察会被感知模块再次捕获,同时LLM会根据行动结果更新记忆 (Memory Update),从而启动下一轮“感知-思考-行动”的循环。这种模块化的协同机制与持续的迭代循环,构成了LLM驱动智能体解决复杂问题的核心工作流。
2.3智能体发展关键节点概览
人工智能体的发展史并非一条笔直的单行道,而是几大核心思想流派长达半个多世纪交织、竞争与融合的历程。理解这一历程,有助于我们洞察当前智能体架构范式形成的深刻根源。
这其中,主要有三大思潮主导着不同时期的研究范式:
1. 符号主义 (Symbolism) :以赫伯特·西蒙 (Herbert A. Simon) 、明斯基 (Marvin Minsky) 等先驱为代表,认为智能的核心在于对符号的操作与逻辑推理。这一思想催生了能够理解自然语言指令的SHRDLU、知识驱动的专家系统以及在国际象棋领域取得巨大成功的“深蓝”计算机。
2. 联结主义 (Connectionism) :其灵感源于对大脑神经网络的模拟。尽管早期发展受限,但在杰弗里·辛顿 (Geoffrey Hinton) 等研究者的推动下,反向传播算法为神经网络的复苏奠定了基础。最终,随着深度学习时代的到来,这一思想通过卷积神经网络、Transformer等模型成为当前的主流。
3. 行为主义 (Behaviorism) :强调智能体通过与环境的互动和试错来学习最优策略,其现代化身为强化学习 。从早期的TD-Gammon到与深度学习结合并击败人类顶尖棋手的AlphaGo,这一流派为智能体赋予了从经验中习得复杂决策行为的能力。
进入21世纪20年代,这些思想流派以前所未有的方式深度融合。以GPT系列为代表的大语言模型,其本身是联结主义的产物,却成为了执行符号推理、进行工具调用和规划决策的核心“大脑”,形成了神经-符号结合的现代智能体架构。为了系统性地回顾这一发展脉络,下图2.11梳理了从20世纪50年代至今,人工智能体发展史上的关键理论、项目与事件,为读者提供一个清晰的全局概览,作为本章知识的沉淀。

得益于大语言模型的突破,智能体技术栈呈现出前所未有的活跃度和多样性。图2.12展示了当前AI Agent领域的一个典型技术栈全貌,涵盖了从底层模型到上层应用的各个环节。

该技术栈图由Letta公司于2024年11月发布[10],它将AI智能体相关的工具、平台和服务进行了分层与分类,为我们理解当前的市场格局和技术选型提供了宝贵的参考。